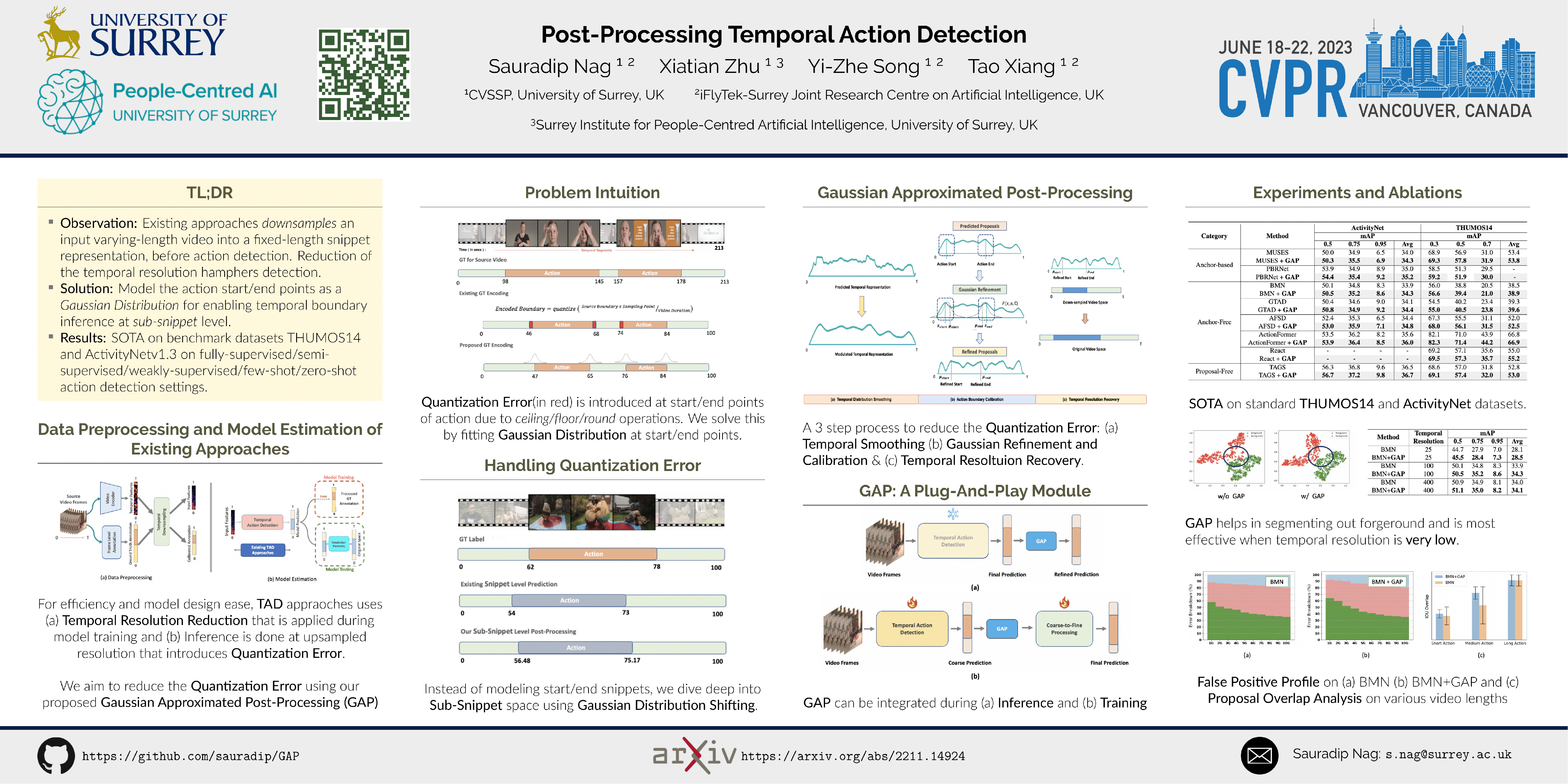
Existing Temporal Action Detection (TAD) methods typically take a pre-processing step in converting an input varying-length video into a fixed-length snippet representation sequence, before temporal boundary estimation and action classification. This pre-processing step would temporally downsample the video, reducing the inference resolution and hampering the detection performance in the original temporal resolution. In essence, this is due to a temporal quantization error introduced during the resolution downsampling and recovery. This could negatively impact the TAD performance, but is largely ignored by existing methods. To address this problem, in this work we introduce a novel model-agnostic post-processing method without model redesign and retraining. Specifically, we model the start and end points of action instances with a Gaussian distribution for enabling temporal boundary inference at a sub-snippet level. We further introduce an efficient Taylor-expansion based approximation, dubbed as Gaussian Approximated Post-processing (GAP). Extensive experiments demonstrate that our GAP can consistently improve a wide variety of pre-trained off-the-shelf TAD models on the challenging ActivityNet (+0.2% -0.7% in average mAP) and THUMOS (+0.2% -0.5% in average mAP) benchmarks. Such performance gains are already significant and highly comparable to those achieved by novel model designs. Also, GAP can be integrated with model training for further performance gain. Importantly, GAP enables lower temporal resolutions for more efficient inference, facilitating low-resource applications.
We identify the previously neglected harming effect of temporal resolution reduction during the pre-processing step in temporal action detection. We solve this by fitting Gaussian Priors around the action boundaries and find the shift using Taylor's Expansion.
Most TAD methods would pre-process a varying-length video into a fixed-length snippet sequence by first extracting frame-level visual features with a frozen video encoder and subsequently sampling a smaller number of feature points (i.e., snippet) evenly. As a result, a TAD model performs the inference at lower temporal resolutions. This introduces a temporal quantization error that could hamper the model performance. For instance, when decreasing video temporal resolution from 400 to 25, the performance of BMN degrades significantly from 34.0% to 28.1% in mAP on ActivityNet. Despite the obvious connection between the error and performance degradation, this problem is largely ignored by existing methods. Quantization Error (in red) is introduced at start/end points of action due to ceiling/floor/round operations

We investigate the temporal quantization error problem from a post-processing perspective. Specifically, we introduce a model-agnostic post-processing approach for improving the detection performance of existing off-the-shelf TAD models without model retraining. To maximize the applicability, we consider the TAD inference as a black-box process. Concretely, taking the predictions by any model, we formulate the start and end points of action instances with a Gaussian distribution in a continuous snippet temporal resolution. We account for the distribution information of temporal boundaries via Taylor-expansion based approximation. This enables TAD inference at subsnippet precision, creating the possibility of alleviating the temporal quantization error. Firstly, we smooth the distribution using Gaussian Kernel to avoid multiple peaks. Secondly, we fit Gaussian Distribution at the boundary point and estimate shift using Taylor's expansion at sub-snippet level. Thirdly, we recover the temporal resolution by multiplying the Video Duration. The refined start/end point reduces the quantization error at sub-snippet level.

When model retraining is allowed, our GAP can also be integrated with existing TAD training without altering design nor adding learnable parameters. The only change is to applying GAP on the intermediate coarser predictions by prior methods (e.g., AFSD and RTDNet). While retraining a model with predicted outputs could bring good margin, our post processing mode is more generally useful with little extra cost

Our proposed GAP is generalizable to any TAD model of any supervision and plugging it with existing approaches outperforms a lot of current state-of-the-art in fully-supervised/semi-supervised/weakly-supervised/few-shot/zero-shot setting of TAD indicating the superiority of our model design.


@inproceedings{nag2023post,
title={Post-Processing Temporal Action Detection},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-Zhe and Xiang, Tao},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18837--18845},
year={2023}
}

{kind=link}