|
Sauradip Nag
What Goes Around
Comes Around.
I am currently a Postdoctoral Researcher at
GrUVi, Simon Fraser University (SFU), Canada. I am working on Multi-Modal Generative Modeling with
Prof. Richard (Hao) Zhang and
Dr. Ali-Mahdavi Amiri. During my Post-doc I also worked with
Prof. Daniel Cohen-Or.
Prior to this, I completed my Doctor of Philosophy (PhD), focusing on Computer Vision and Deep Learning in 2023, from
Xiang's Phd Group of Centre for Vision, Speech and Signal Processing (CVSSP), University of Surrey,
England, United Kingdom. I was advised by primary supervisor
Prof. Tao (Tony) Xiang, and co-supervisor as
Prof. Yi-Zhe Song. During my PhD, I also worked closely with
Dr. Xiatian (Eddy) Zhu.
Email
/
CV /
Google Scholar
/
LinkedIn
/
GitHub
/
Twitter
|

|

|
|
|
|
|
|
| Simon Fraser University,
Canada
Position : Post-Doctorate Researcher in GrUVi Lab, School of Computing Science
Worked on 3D Articulation/Segmentation, 4D Generation and Hybrid Representations
Feb 2024 - Present
|

|
|
|
|
|
|
| Indian Institute of
Technology Madras,
India
Position : Research Engineer/Associate in ICSR and CAIR, DRDO
Deployed RGBD-SLAM and Distilled Computer Vision Models on Robots
Jul 2018 - Feb 2020
|

|
|
|
|
|
|
| GISCLE Systems, India
Position : Research Engineer Intern in Autonomous Driving Team.
Curating Data and Training Computer Vision Models for Autonomous Driving
Jan 2018 - Aug 2018
|

|
|
|
|
|
|
| Kalyani Government Engineering College,
India
Position : Bachelor of Technology (B.Tech) in Computer Science and Engineering
Under Dr. Kousik Dasgupta
Thesis : Interacting with Softwares using Gestures
Jul 2014 - Jul 2018
|
|
|
Articulate That Object Part: 3D Part Articulation via Text and Motion
Personalization
Aditya Vora
,
Sauradip Nag
,
Kai Wang
,
Richard (Hao) Zhang
ACM Transaction of Graphics (TOG), 2026
(Provisional Accept)
[ H5-Index : 114 ]
Seminal work to solve Controlled 3D Mesh articulation via personalization of Part Motion using Diffusion models. We train a part-controllable Multi-View Video Generator that generates Multi-View Part Motions, which optimizes the 3D Motion axis of the mesh. Existing Video Diffusion models still lack articulation awareness, this is a drop-in replacement for it
Abstract
/
Code
/
ArXiv /
BibTex
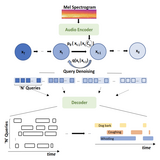
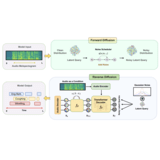
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
Advances in 4D Representation: Geometry, Motion and Interaction
Mingrui Zhao
,
Sauradip Nag,
,
Kai Wang
,
Aditya Vora
,
Guangda Ji
,
Peter Chun
,
Ali-Madhavi Amiri
,
Richard (Hao) Zhang
Arxiv, 2025
A new survey on 4D representations of objects and scenes. We have dived deep into the literature in the perspective of the underlying geometry, the motion types used for driving the geometry and interaction mechanism with such geometry and motion..
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
In-2-4D: Inbetweening from Two Single-View Images to 4D Generation
Sauradip Nag
,
Daniel Cohen-Or
,
Richard (Hao) Zhang
,
Ali-Mahdavi Amiri
ACM SIGGRAPH Asia, 2025
HongKong, China
[ H5-Index : 114 ]
The first work to solve Generative 4D Interpolation from sparse view images. We divide the motion trajectory into rigid parts and model the 4D motion with 3D Gaussian Splatting as geometry.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
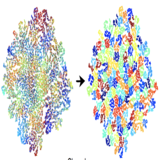
ASIA: Adaptive 3D Segmentation using Few Image Annotations
Sai Raj Kishore
,
Aditya Vora*
,
Sauradip Nag*
,
Ali-Mahdavi Amiri,
Richard (Hao) Zhang
ACM SIGGRAPH Asia, 2025
HongKong, China
[ H5-Index : 114 ]
The first work to do adaptive Part Segmentation in 3D Meshes from user annotated Images. Different from semantic Part Segmentations, this offers more user control and editing power to 3D Mesh.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
Cora: Correspondence-aware image editing using few step diffusion
Amir AM.*
,
Aryan Mikaieli*
,
Sauradip Nag,
,
Negar H.
,
Andrea Tagliasacchi
,
AM Amiri
ACM SIGGRAPH North America, 2025
Vancouver, Canada
[ H5-Index : 114 ]
A new image editing method that enables flexible and accurate edits-like pose changes, object insertions, and background swaps-using only 4 diffusion steps. It uses semantic correspondences between the original and edited image to preserve structure and appearance where needed.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
SMITE: Segment Me in Time
Amir AM.
,
Sauradip Nag,
,
Negar H.
,
Andrea Tagliasacchi
,
Ghasan H.
,
Ali-Mahdavi Amiri
International Conference on Learning Representation (ICLR), 2025
Singapore
[ H5-Index : 362 ]
A new Customized Video Segmentation approach which follows the segmentations from user annotated images of the object. It uses the emergent properties of Video Diffusion models to segment non-semantic annotations in the video in a consistent manner.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
RespoDiff: Dual-Module Bottleneck Transformation for Responsible T2I Generation
Silpa V.S
,
Sauradip Nag
,
Muhammad Awais
,
Serge Belongie
,
Anjan Dutta
Neural Information and Processing Systems (NeurIPS), 2025
San Diego, USA
[ H5-Index : 371 ]
A Novel Framework for responsible T2I generation via dual transformations on the intermediate representations of diffusion model
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
CountLoop: Training-Free High-Instance Image Generation via Iterative Agent Guidance
Anindya Mondal
,
Ayan Banerjee
,
Sauradip Nag
,
Josep Lados
,
Xiatian Zhu
,
Anjan Dutta
Arxiv, 2025
A Novel High-Instance Image Generation method that uses MLLM as a designer and critic to generate asthetically beautiful images that do not suffer from semantic leakage
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
OmniCount: Multi-label Object Counting with Semantic-Geometric Priors
Anindya Mondal*
,
Sauradip Nag*
,
Joaquin Prada
,
Xiatian Zhu
,
Anjan Dutta
AAAI, 2025
Washington DC, USA
[ H5-Index : 232 ]
A novel VLM based zero-shot Image counting approach that uses geometric properties of the image to count objects in dense scenes and suffering partial occlusions. We additionally propose the largest Image counting benchmark OmniCOunt-191 which has 191 Categories and over 30K annotations.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
DiffSED: Diffusion-based Sound Event Detection
Swapnil Bhosale*
,
Sauradip Nag*
,
Diptesh Kanojia
,
Jiankang Deng
,
Xiatian Zhu
AAAI Conference on Artificial Intelligence (AAAI), 2024
(Oral Paper)
Vancouver, Canada
[ H5-Index : 212 ]
This work reformulated the discriminative Sound-Event Detection task into a Generative Learning paradigm using Noise-to-Latent Densoising Diffusion.
Abstract
/
Code
/
ArXiv /
BibTex
Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40%+ faster convergence in training.
@article{bhosale2023diffsed,
title={DiffSED: Sound Event Detection with Denoising Diffusion},
author={Bhosale, Swapnil and Nag, Sauradip and Kanojia, Diptesh and Deng, Jiankang and Zhu, Xiatian},
journal={arXiv preprint arXiv:2308.07293},
year={2023}
}
|
|
|
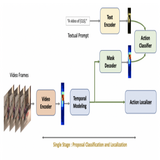
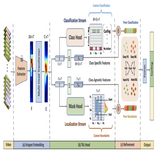
DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
Sauradip Nag
,
Xiatian Zhu
,
Jiankang Deng
,
Yi-Zhe Song
,
Tao Xiang
IEEE International Conference on Computer Vision (ICCV), 2023
Paris, France
[ H5-Index : 239 ]
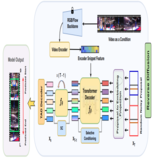
This work introduced the first DETR based Diffusion framework for Human Activity Detection task. It introduces a new Noise-to-Proposal denoising paradigm of Diffusion via Transformer Decoder as denoiser. This can be extended to any detection task.
Abstract
/
Code
/
ArXiv /
BibTex
We propose a new formulation of temporal action de-
tection (TAD) with denoising diffusion, DiffTAD in short.
Taking as input random temporal proposals, it can yield ac-
tion proposals accurately given an untrimmed long video.
This presents a generative modeling perspective, against
previous discriminative learning manners. This capability
is achieved by first diffusing the ground-truth proposals to
random ones (i.e., the forward/noising process) and then
learning to reverse the noising process (i.e., the backward/-
denoising process). Concretely, we establish the denoising
process in the Transformer decoder (e.g., DETR) by intro-
ducing a temporal location query design with faster con-
vergence in training. We further propose a cross-step selec-
tive conditioning algorithm for inference acceleration. Ex-
tensive evaluations on ActivityNet and THUMOS show that
our DiffTAD achieves top performance compared to previ-
ous art alternatives.
@inproceedings{nag2023difftad,
title={Post-Processing Temporal Action Detection},
author={Nag, Sauradip and Zhu, Xiatian and Deng Jiankang, and Song, Yi-zhe and Xiang, Tao},
booktitle=arxiv,
year={2023}
}
|
|
|
PersonalTailor: Personalizing 2D Pattern Design from 3D Point Clouds
Sauradip Nag
,
Anran Qi
,
Xiatian Zhu
,
Ariel Shamir
ArXiv, 2023
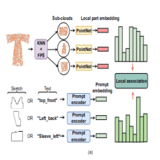
This work introduced a multi-modal latent-space disentanglement pipeline for 2D Garment Pattern editing from 3D point clouds. Disentangling latent gives the flexibility to add/edit/delete the panel latents individually whose composition forms new Garment Styles.
Abstract
/
Code
/
ArXiv /
BibTex
Garment pattern design aims to convert a 3D garment
to the corresponding 2D panels and their sewing struc-
ture. Existing methods rely either on template fitting with
heuristics and prior assumptions, or on model learning with
complicated shape parameterization. Importantly, both ap-
proaches do not allow for personalization of the output gar-
ment, which today has increasing demands. To fill this de-
mand, we introduce PersonalTailor: a personalized 2D pat-
tern design method, where the user can input specific con-
straints or demands (in language or sketch) for personal 2D
panel fabrication from 3D point clouds. PersonalTailor first
learns a multi-modal panel embeddings based on unsuper-
vised cross-modal association and attentive fusion. It then
predicts a binary panel masks individually using a trans-
former encoder-decoder framework. Extensive experiments
show that our PersonalTailor excels on both personalized
and standard pattern fabrication tasks
@inproceedings{nag2022muppet,
title={Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation},
author={Nag, Sauradip and Xu, Mengmeng and Zhu, Xiatian and Perez-Rua, Juan-Manuel and Ghanem, Bernard and Song, Yi-zhe and Xiang, Tao},
booktitle=arxiv,
year={2022}
}
|
|
|
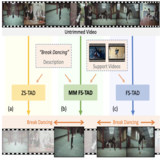
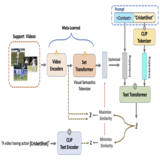
Multi-Modal Few-Shot Temporal Action Detection
Sauradip Nag
,
Mengmeng Xu
,
Xiatian Zhu
,
Juan Perez-Rua
,
Bernard Ghanem
,
Yi-Zhe Song
,
Tao Xiang
Arxiv 2023
This work introduced a novel Multi-Modal Few-Shot setting for Human Activity Detection task, where each Support Set consists of both Videos and associated Captions/Text. This work also shows how Video-to-NullText inversion is done, similar to DreamBooth.
Abstract
/
Code
/
arXiv /
BibTex
Few-shot (FS) and zero-shot (ZS) learning are two different approaches for scaling temporal action detection
(TAD) to new classes. The former adapts a pretrained vision model to a new task represented by as few as a single
video per class, whilst the latter requires no training examples by exploiting a semantic description of the new class.
In this work, we introduce a new multi-modality few-shot
(MMFS) TAD problem, which can be considered as a marriage of FS-TAD and ZS-TAD by leveraging few-shot support videos and new class names jointly. To tackle this problem, we further introduce a novel MUlti-modality PromPt
mETa-learning (MUPPET) method. This is enabled by efficiently bridging pretrained vision and language models
whilst maximally reusing already learned capacity. Concretely, we construct multi-modal prompts by mapping support videos into the textual token space of a vision-language
model using a meta-learned adapter-equipped visual semantics tokenizer. To tackle large intra-class variation, we
further design a query feature regulation scheme. Extensive
experiments on ActivityNetv1.3 and THUMOS14 demonstrate that our MUPPET outperforms state-of-the-art alternative methods, often by a large margin. We also show that
our MUPPET can be easily extended to tackle the few-shot
object detection problem and again achieves the state-ofthe-art performance on MS-COCO dataset
@inproceedings{nag2022muppet,
title={Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation},
author={Nag, Sauradip and Xu, Mengmeng and Zhu, Xiatian and Perez-Rua, Juan-Manuel and Ghanem, Bernard and Song, Yi-zhe and Xiang, Tao},
booktitle=arxiv,
year={2022}
|
|
|
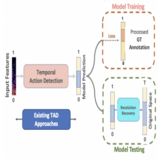
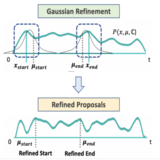
Post-Processing Temporal Action Detection
Sauradip Nag
,
Xiatian Zhu
,
Yi-Zhe Song
,
Tao Xiang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Vancouver, Canada
[ H5-Index : 389 ]
This work introduced a new Parameter-Free learnable Post-Processing technique for Human Action Detection task. It uses Gaussian Based refinement of start/end points where the refined shift is estimated using Taylor's Expansion.
Abstract
/
Code
/
ArXiv /
BibTex
Existing Temporal Action Detection (TAD) methods typically take a pre-processing step in converting an input
varying-length video into a fixed-length snippet representation sequence, before temporal boundary estimation and
action classification. This pre-processing step would temporally downsample the video, reducing the inference resolution and hampering the detection performance in the
original temporal resolution. In essence, this is due to a
temporal quantization error introduced during the resolution downsampling and recovery. This could negatively impact the TAD performance, but is largely ignored by existing
methods. To address this problem, in this work we introduce a novel model-agnostic post-processing method without model redesign and retraining. Specifically, we model
the start and end points of action instances with a Gaussian distribution for enabling temporal boundary inference
at a sub-snippet level. We further introduce an efficient
Taylor-expansion based approximation, dubbed as Gaussian Approximated Post-processing (GAP). Extensive experiments demonstrate that our GAP can consistently improve a wide variety of pre-trained off-the-shelf TAD models on the challenging ActivityNet (+0.2%∼0.7% in average mAP) and THUMOS (+0.2%∼0.5% in average mAP)
benchmarks. Such performance gains are already significant and highly comparable to those achieved by novel
model designs. Also, GAP can be integrated with model
training for further performance gain. Importantly, GAP
enables lower temporal resolutions for more efficient inference, facilitating low-resource applications
@inproceedings{nag2022gap,
title={Post-Processing Temporal Action Detection},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-zhe and Xiang, Tao},
booktitle=arxiv,
year={2022}
}
|
|
|
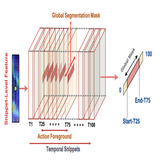
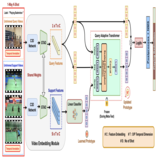
Proposal-Free Temporal Action Detection via Global Segmentation Mask
Sauradip Nag
,
Xiatian Zhu
,
Yi-Zhe Song
,
Tao Xiang
European Conference in Computer Vision (ECCV), 2022
Tel Aviv, Israel
[ H5-Index : 187 ]
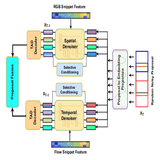
This is the first work that introduces a new Proposal-Free paradigm in Human Action Detection task. It reformulates action start/end regression into a action-mask prediction problem. This makes it 30x faster in training and 2x in inference than existing approaches
Abstract
/
Code
/
ArXiv /
Project Page /
BibTex
Existing temporal action localization (TAL) methods rely
on generating an overwhelmingly large number of proposals per video.
This leads to complex model designs due to proposal generation and/or
per-proposal action instance evaluation and the resultant high computational cost. In this work, for the first time, a proposal-free TAL model is
proposed. Our core idea is to learn a global segmentation mask (GSM) of
each action instance jointly at the full video length. GSM model differs
significantly from the conventional proposal-based methods by focusing
on global temporal representation learning to directly detect local start
and end points of action instances without proposals. Further, by modeling TAL holistically rather than locally at the individual proposal level,
GSM needs a much simpler model architecture with lower computational
cost. Extensive experiments show that despite its simpler design, GSM
outperforms existing TAL methods, achieving new state-of-the-art performance on two benchmarks. Importantly, it is ∼ 20× faster to train
and ∼ 1.6× more efficient for inference
@inproceedings{nag2022gsm,
title={Temporal Action Localization with Global Segmentation Mask Learning},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-zhe and Xiang, Tao},
booktitle=eccv,
year={2022}
}
|
|
|
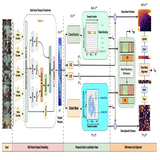
Zero-Shot Temporal Action Detection via Vision-Language Prompting
Sauradip Nag
,
Xiatian Zhu
,
Yi-Zhe Song
,
Tao Xiang
European Conference in Computer Vision (ECCV), 2022
Tel Aviv, Israel
[ H5-Index : 187 ]
This is the first work that introduces Vision-language models for Zero-Shot Action Detection task. CLIP models off-the-shelf are not meant for detection tasks, it needs a class-agnostic masking to make it generalizable to zero-shot setting which is illustrated in this work.
Abstract
/
Code
/
ArXiv /
Project Page /
BibTex
Existing temporal action localization (TAL) methods rely
on a large number of training data with segment-level annotations, restricted to the training classes alone during inference. However, collecting
and annotating a large training set for all the classes of interest is costly
and hence unscalable over time. Zero-shot TAL (ZS-TAL) resolves this
obstacle by enabling a pre-trained model to recognize any unseen action
classes. Nonetheless, ZS-TAL is also much more challenging than supervised counterpart, consequently significantly under-studied. Inspired
by the success of zero-shot image classification with the aid of recent
vision-language (ViL) models such as CLIP, we also aim to capitalize
them for the complex TAL task. A recent ZS-TAL work of this kind directly combines an off-the-shelf proposal detector with CLIP style classification in a 2-stage design. Due to the sequential localization (e.g.,
proposal generation) and classification design, it is prone to localization
error propagation. To overcome this problem, in this paper we propose a
novel Parallel Classification and Localization with class-agnostic Feature
Masking (PCL-FM) model. Such a novel design effectively eliminates
the dependence between localization and classification by breaking the
route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved
optimization. Extensive experiments on standard ZS-TAl video benchmarks show that our PCL-FM significantly outperforms state-of-the-art
alternatives. Besides, our model also yield superior results on supervised
TAL over recent strong competitors.
@inproceedings{nag2022pclfm,
title={Language Guided Zero-Shot Temporal Action Localization with Feature Masking},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-zhe and Xiang, Tao},
booktitle=eccv,
year={2022}
}
|
|
|
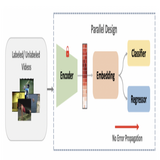
Semi-Supervised Temporal Action Detection
with Proposal-Free Masking
Sauradip Nag
,
Xiatian Zhu
,
Yi-Zhe Song
,
Tao Xiang
European Conference in Computer Vision (ECCV), 2022
Tel Aviv, Israel
[ H5-Index : 187 ]
This work showcases that having a two-stage pipeline for Human Action Detection task suffers from Proposal Error-Propagation problem. This work propsoed a new single-stage framework coupled with novel self-supervised pre-training task to curb out this error.
Abstract
/
Code
/
ArXiv /
Project Page /
BibTex
Existing temporal action localization (TAL) methods rely on
a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAL (SSTAL) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SSTAL is also a
much more challenging problem than supervised TAL, and consequently
much under-studied. Prior SSTAL methods directly combine an existing
proposal-based TAL method and a SSL method. Due to their sequential
localization (e.g., proposal generation) and classification design, they are
prone to proposal error propagation. To overcome this limitation, in this
work we propose a novel Proposal-Free Temporal Mask (PFTM) learning
model with a parallel localization (mask generation) and classification
architecture. Such a novel design effectively eliminates the dependence
between localization and classification by cutting off the route for error
propagation in-between. We further introduce an interaction mechanism
between classification and localization for prediction refinement, and a
new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our PFTM outperforms
state-of-the-art alternatives, often by a large margin
@inproceedings{nag2022pftm,
title={Semi-Supervised Temporal Action Localization with Proposal-Free Temporal Mask Learning},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-zhe and Xiang, Tao},
booktitle=eccv,
year={2022}
}
|
|
|
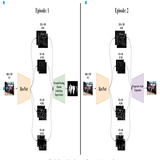
Few-Shot Temporal Action Localization with Query Adaptive Transformer
Sauradip Nag
,
Xiatian Zhu
,
Tao Xiang
British Machine Vision Conference (BMVC), 2021
Manchester, Virtual
[ H5-Index : 66 ]
Existing Few-Shot Action Detection tasks deal with trimmed video and has different designs for different few-shot algorithms. This work proposed a Model-Agnostic approach to use Untrimmed Video for adapting Query Videos using Support Samples
Abstract
/
Code
/
ArXiv /
BibTex
/
Slides
Existing temporal action localization (TAL) works rely on a large number of training videos with exhaustive segment-level annotation, preventing them from scaling to new classes. As a solution to this problem, few-shot TAL (FS-TAL) aims to adapt a model to a new class represented by as few as a single video. Exiting FS-TAL methods assume trimmed training videos for new classes. However, this setting is not only unnatural – actions are typically captured in untrimmed videos, but also ignores background video segments containing vital contextual cues for foreground action segmentation. In this work, we first propose a new FS-TAL setting by proposing to use untrimmed training videos. Further, a novel FS-TAL model is proposed which maximizes the knowledge transfer from training classes whilst enabling the model to be dynamically adapted to both the new class and each video of that class simultaneously. This is achieved by introducing a query adaptive Transformer in the model. Extensive experiments on two action localization benchmarks demonstrate that our method can outperform all the state-of-the-art alternatives significantly in both single-domain and cross-domain scenarios.
title={Few-Shot Temporal Action Localization with Query Adaptive Transformer},
author={Sauradip Nag and Xiatian Zhu and Tao Xiang},
year={2021},
eprint={2110.10552},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
|
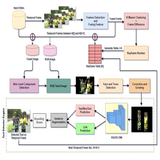
An Episodic Learning Network for Text Detection on Human Bodies in Sports Images
P Chowdhury
,
P Shivakumara
,
R Ramachandra
,
Sauradip Nag
,
Umapada Pal
,
Tong Lu
,
Daniel Lopresti
IEEE Transactions on CSVT
[IF : 4.6]
Introduces a new improved Human Centric approach of Detecting Bib Numbers from sports video by taking motion influenced Human Clothing and Camera Pose into consideration.
Abstract
/
BibTex
Due to explosive proliferation of multimedia content especially from sports images, retrieving desired
information using common devices is an interesting research area. It is also challenging because of low
image quality, large variations of camera view-points, large pose variations, occlusions etc. This paper
presents a new method for text detection on jersey/clothing in sports images. Unlike most existing
methods which explore torso, face and skin for detecting texts in sports images, we explore
cloth/uniform/jersey information for text detection. The basis for exploiting cloth, which can be jersey
or uniform of the player, is the presence of vital text in the cloth in sports images. The proposed
method integrates Residual Network (ResNet) and Pyramidal Pooling Module (PPM) for generating a spatial
attention map over cloth region and the Progressive Scalable Expansion Algorithm (PSE) for text
detection from cloth regions. Experimental results on our dataset that contains sports images and the
benchmark datasets, namely, RBNR, MMM which provide Marathon images, Re-ID which is a person
re-identification dataset, show that the proposed method outperforms the existing methods in terms of
precision and F1-score. In addition, the proposed approach is also tested on sports images chosen from
benchmark datasets of natural scene text detection like CTW1500 and MS-COCO and we noted that the
proposed method is robust, effective and reliable.
@ARTICLE{9466949,
author={Shivakumara, Pinaki Nath Chowdhury are with Palaiahnakote and Raghavendra, Ramachandra and Nag, Sauradip and Pal, Umapada and Lu, Tong and Lopresti, Daniel},
journal={IEEE Transactions on Circuits and Systems for Video Technology},
title={An Episodic Learning Network for Text Detection on Human Bodies in Sports Images},
year={2021},
volume={},
number={},
pages={1-1},
doi={10.1109/TCSVT.2021.3092713}}
|
|
|
A New Unified Method for Detecting Text from Marathon Runners and Sports Players in
Video
Sauradip Nag
,
P Shivakumara
,
Umapada Pal
,
Tong Lu
,
Michael Blumenstein
Pattern Recognition, Elsevier
[IF : 7.196]
Introduces a new way of Detecting Bib Numbers from sports video by taking Human Torso, Skin and Head into consideration.
Abstract
/
Code
/
BibTex
Detecting text located on the torsos of marathon runners and sports players in video is a
challenging
issue due to poor quality and adverse effects caused by flexible/colorful clothing, and
different
structures of human bodies or actions. This paper presents a new unified method for tackling the
above
challenges. The proposed method fuses gradient magnitude and direction coherence of text pixels
in a
new way for detecting candidate regions. Candidate regions are used for determining the number
of
temporal frame clusters obtained by K-means clustering on frame differences. This process in
turn
detects key frames. The proposed method explores Bayesian probability for skin portions using
color
values at both pixel and component levels of temporal frames, which provides fused images with
skin
components. Based on skin information, the proposed method then detects faces and torsos by
finding
structural and spatial coherences between them. We further propose adaptive pixels linking a
deep
learning model for text detection from torso regions. The proposed method is tested on our own
dataset
collected from marathon/sports video and three standard datasets, namely, RBNR, MMM and R-ID of
marathon images, to evaluate the performance. In addition, the proposed method is also tested on
the
standard natural scene datasets, namely, CTW1500 and MS-COCO text datasets, to show the
objectiveness
of the proposed method. A comparative study with the state-of-the-art methods on bib number/text
detection of different datasets shows that the proposed method outperforms the existing methods
@article{nag2020new,
title={A New Unified Method for Detecting Text from Marathon Runners and Sports Players in Video
(PR-D-19-01078R2)},
author={Nag, Sauradip and Shivakumara, Palaiahnakote and Pal, Umapada and Lu, Tong and Blumenstein,
Michael},
journal={Pattern Recognition},
pages={107476},
year={2020},
publisher={Elsevier}
}
|
|
|
What's There in the Dark
Sauradip Nag
,
Saptakatha Adak
,
Sukhendu Das
International Conference in Image Processing (ICIP), 2019
(Spotlight Paper)
Taipei, Taiwan
[ H5-Index : 45 ]
This is the first work that introduced Semantic Segmentation for Night-Time scenes. This approach used Cycle-GANS as a means to generate Night time segmentations and used a comparator network as a discriminator to distinguish real vs fake night-time sample.
Abstract
/
Code
/
BibTex
Scene Parsing is an important cog for modern autonomous driving systems. Most of the works in
semantic segmentation pertains to day-time scenes with favourable weather and illumination
conditions. In this paper, we propose a novel deep architecture, NiSeNet, that performs semantic
segmentation of night scenes using a domain mapping approach of synthetic to real data. It is a
dual-channel network, where we designed a Real channel using DeepLabV3+ coupled with an MSE loss
to preserve the spatial information. In addition, we used an Adaptive channel reducing the
domain gap between synthetic and real night images, which also complements the failures of Real
channel output. Apart from the dual channel, we introduced a novel fusion scheme to fuse the
outputs of two channels. In addition to that, we compiled a new dataset Urban Night Driving
Dataset (UNDD); it consists of 7125 unlabelled day and night images; additionally, it has 75
night images with pixel-level annotations having classes equivalent to Cityscapes dataset. We
evaluated our approach on the Berkley Deep Drive dataset, the challenging Mapillary dataset and
UNDD dataset to exhibit that the proposed method outperforms the state-of-the-art techniques in
terms of accuracy and visual quality.
@inproceedings{nag2019s,
title={What’s There in the Dark},
author={Nag, Sauradip and Adak, Saptakatha and Das, Sukhendu},
booktitle={2019 IEEE International Conference on Image Processing (ICIP)},
pages={2996--3000},
year={2019},
organization={IEEE}
}
|
|
|
Facial Micro-Expression Spotting and Recognition using Time Contrasted Feature with
Visual Memory
Sauradip Nag
,
Ayan Kumar Bhunia
,
Aishik Konwer,
Partha Pratim Roy
International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019
Brighton, United Kingdom
[ H5-Index : 80 ]
This work introduced a new spatio-temporal network for Facial Micro-Expression detection task. It introduced a time-constrasted feature extraction module that greatly improved the spotting
of micro-expression from inconspicuous facial movements.
Abstract
/
arXiv
/
BibTex
Facial micro-expressions are sudden involuntary minute muscle movements which reveal true
emotions that people try to conceal. Spotting a micro-expression and recognizing it is a major
challenge owing to its short duration and intensity. Many works pursued traditional and deep
learning based approaches to solve this issue but compromised on learning low level features and
higher accuracy due to unavailability of datasets. This motivated us to propose a novel joint
architecture of spatial and temporal network which extracts time-contrasted features from the
feature maps to contrast out micro-expression from rapid muscle movements. The usage of time
contrasted features greatly improved the spotting of micro-expression from inconspicuous facial
movements. Also, we include a memory module to predict the class and intensity of the
micro-expression across the temporal frames of the micro-expression clip. Our method achieves
superior performance in comparison to other conventional approaches on CASMEII dataset.
@inproceedings{nag2019facial,
title={Facial Micro-Expression Spotting and Recognition using Time Contrasted Feature with Visual
Memory},
author={Nag, Sauradip and Bhunia, Ayan Kumar and Konwer, Aishik and Roy, Partha Pratim},
booktitle={ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal
Processing (ICASSP)},
pages={2022--2026},
year={2019},
organization={IEEE}
}
|
|
|
CRNN based Jersey-Bib Number/Text Recognition in Sports and Marathon Images
Sauradip Nag
,
Raghavendra Ramachandra
,
Palaiahnakote Shivakumara
,
Umapada Pal
,
Tong Lu
,
Mohan Kankanhalli
International Conference on Document Analysis and Recognition (ICDAR), 2019
Sydney, Australia
[ H5-Index : 26 ]
This work further improves the Bib Detection from images. It uses a 2D-Human Pose Keypoints to identify different possible locations for Bib numbers and then individually extracts them using LSTM based text recognition pipeline
Abstract
/
BibTex
The primary challenge in tracing the participants in sports and marathon video or images is to
detect and localize the jersey/Bib number that may present in different regions of their outfit
captured in cluttered environment conditions. In this work, we proposed a new framework based on
detecting the human body parts such that both Jersey Bib number and text is localized reliably.
To achieve this, the proposed method first detects and localize the human in a given image using
Single Shot Multibox Detector (SSD). In the next step, different human body parts namely, Torso,
Left Thigh, Right Thigh, that generally contain a Bib number or text region is automatically
extracted. These detected individual parts are processed individually to detect the Jersey Bib
number/text using a deep CNN network based on the 2-channel architecture based on the novel
adaptive weighting loss function. Finally, the detected text is cropped out and fed to a CNN-RNN
based deep model abbreviated as CRNN for recognizing jersey/Bib/text. Extensive experiments are
carried out on the four different datasets including both bench-marking dataset and a new
dataset. The performance of the proposed method is compared with the state-of-the-art methods on
all four datasets that indicates the improved performance of the proposed method on all four
datasets.
@inproceedings{nag2019crnn,
title={CRNN Based Jersey-Bib Number/Text Recognition in Sports and Marathon Images},
author={Nag, Sauradip and Ramachandra, Raghavendra and Shivakumara, Palaiahnakote and Pal, Umapada
and Lu, Tong and Kankanhalli, Mohan},
booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)},
pages={1149--1156},
year={2019},
organization={IEEE}
}
|
|
|
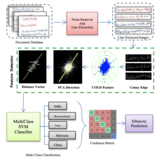
A New COLD Feature based Handwriting Analysis for Ethnicity/Nationality
Identification
Sauradip Nag
,
Palaiahnakote Shivakumara
,
Wu Yirui
,
Umapada Pal
,
Tong Lu
International Conference on Frontiers in Handwriting Recognition (ICFHR), 2018
Niagara Falls, USA
[ H5-Index : 18 ]
This is the first work that can identify Ethnicity from Handwriting in documents. It uses a Cloud-of-Line distribution based feature representation whose dimension is reduced by a PCA to select the prominent differences and used by SVM for classification of ethnicity.
Abstract
/
arXiv
/
BibTex
Identifying crime for forensic investigating teams
when crimes involve people of different nationals is challenging.
This paper proposes a new method for ethnicity (nationality)
identification based on Cloud of Line Distribution (COLD)
features of handwriting components. The proposed method, at
first, explores tangent angle for the contour pixels in each row
and the mean of intensity values of each row in an image for
segmenting text lines. For segmented text lines, we use tangent
angle and direction of base lines to remove rule lines in the
image. We use polygonal approximation for finding dominant
points for contours of edge components. Then the proposed
method connects the nearest dominant points of every dominant
point, which results in line segments of dominant point pairs. For
each line segment, the proposed method estimates angle and
length, which gives a point in polar domain. For all the line
segments, the proposed method generates dense points in polar
domain, which results in COLD distribution. As character
component shapes change, according to nationals, the shape of
the distribution changes. This observation is extracted based on
distance from pixels of distribution to Principal Axis of the
distribution. Then the features are subjected to an SVM classifier
for identifying nationals. Experiments are conducted on a
complex dataset, which show the proposed method is effective
and outperforms the existing method.
@inproceedings{nag2018new,
title={New COLD Feature Based Handwriting Analysis for Enthnicity/Nationality Identification},
author={Nag, Sauradip and Shivakumara, Palaiahnakote and Wu, Yirui and Pal, Umapada and Lu,
Tong},
booktitle={2018 16th International Conference on Frontiers in Handwriting Recognition
(ICFHR)},
pages={523--527},
year={2018},
organization={IEEE}
}
|
|
|
DreamPet: Text Driven Controllable 3D Animal Generation using Gaussian Splatting
Vysakh Ramakrishnan
,
Sauradip Nag
,
Xiatian Zhu
,
Amal Dev Parakkat
,
Anjan Dutta
CV4Animals Workshop, CVPR 2024
This work introduces a RAG based Text-to-3D Animal Generation and model realistic fur or animal skin using 3DGS
Abstract
/
Code
/
ArXiv /
BibTex
Realistic 3D animal generation from text prompts is a
significant yet challenging task. Traditional approaches,
which use score distillation sampling to optimize 3D formats like meshes or neural fields, often suffer from a lack
of detail and designed for fixed shape. To address both
limitations, in this work, we introduce DreamPet, a novel
framework that explores a retrieval-augmented approach
tailored for score distillation and efficiently produces highquality 3D animal models featuring fine-grained geometry
and lifelike textures. Our key insight is that both expressiveness of 2D diffusion models and geometric consistency of
3D animal assets can be fully leveraged by employing the
semantically relevant assets directly within the optimization process. Specifically, our method features 1) a ShapeAware SDS for optimizing appearance and geometry to ensure structural consistency per category, and 2) a Categoryaware refinement module that addresses the over-saturation
issue and further eliminates floating artefacts based on the
animal category to produce realistic textures. Extensive experiments demonstrate competitive quality of our method,
rendering 3D animals under diverse scenarios.
@inproceedings{dreampet2024,
title={DreamPet: Text Driven Controllable 3D Animal Generation using Gaussian Splatting},
author={Ramakrishnan, Vysakh and Nag, Sauradip and Zhu, Xiatian and Parakkat, Amal Dev and Dutta, Anjan},
booktitle={CVPR 2024 Workshop on CV4Animals},
year={2024}
}
|
|
|
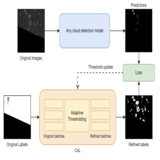
Adaptive-Labeling for Enhancing Remote Sensing Cloud Understanding
Jay Gala
,
Sauradip Nag
,
Huichou Huang
,
Ruirui Liu
,
Xiatian Zhu
Tackling Climate Change with Machine Learning Workshop, NeurIPS 2023
This work introduces a new algorithm to iteratively improve the existing noisy annotations and extract the best performance from any model via combination of Dynamic Thresholding coupled with FixMatch style optimization.
Abstract
/
Code
/
ArXiv /
BibTex
Cloud analysis is a critical component of weather and climate science, impacting various sectors like disaster management. However, achieving fine-grained cloud analysis, such as cloud segmentation, in remote sensing remains challenging due to the inherent difficulties in obtaining accurate labels, leading to significant labeling errors in training data. Existing methods often assume the availability of reliable segmentation annotations, limiting their overall performance. To address this inherent limitation, we introduce an innovative model-agnostic Cloud Adaptive-Labeling (CAL) approach, which operates iteratively to enhance the quality of training data annotations and consequently improve the performance of the learned model. Our methodology commences by training a cloud segmentation model using the original annotations. Subsequently, it introduces a trainable pixel intensity threshold for adaptively labeling the cloud training images on-the-fly. The newly generated labels are then employed to fine-tune the model. Extensive experiments conducted on multiple standard cloud segmentation benchmarks demonstrate the effectiveness of our approach in significantly boosting the performance of existing segmentation models. Our CAL method establishes new state-of-the-art results when compared to a wide array of existing alternatives.
@inproceedings{gala2023cal,
title={Adaptive-Labeling for Enhancing Remote Sensing Cloud Understanding},
author={Gala, Jay and Nag, Sauradip and Huang, Huichou and Liu, Ruirui and Zhu, Xiatian},
booktitle={NeurIPS 2023 Workshop on Tackling Climate Change with Machine Learning},
year={2023}
}
|
|
|
Actor-Agnostic Multi-Label Action Recognition with Multi-Modal Query
Anindya Mondal*
,
Sauradip Nag*
,
Joaquin M. Prada
,
Xiatian Zhu
,
Anjan Dutta
New Ideas in Vision Transformers Workshop (NIVT), ICCV 2023
This work showcases that Action-recognition is not Actor specific if we can make use of Language embeddings. Hence be it Animal or Human action, it is a unified model without any actor specific information requirement for recognition.
Abstract
/
Code
/
ArXiv /
BibTex
Existing action recognition methods are typically actor-specific due to the intrinsic topological and apparent differences among the actors, (e.g., humans vs animals), leading to cumbersome model design complexity and high maintenance costs. Moreover, they often focus on learning the visual modality alone and single-label classification whilst neglecting other available information sources, (e.g., class name text). To address all these limitations, we first introduce a new problem of actor-agnostic multi-modal multi-label action recognition, a single model architecture generalising to different types of actors, such as humans and animals. We further formulate a novel Multi-modal Semantic Query Network (MSQNet) model in a transformer-based object detection framework, (e.g., DETR), characterised by leveraging both visual and textual modalities to represent the action classes more richly. Thus, we completely eliminate the conventional need for actor-specific model designs, (e.g., pose estimation). Extensive experiments on four publicly available benchmarks show that our MSQNet consistently outperforms the prior arts of actor-specific alternatives on both human and animal single- and multi-label action recognition tasks by a margin of up to 50% mean average precision score.
@inproceedings{nag2022muppet,
title={Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation},
author={Nag, Sauradip and Xu, Mengmeng and Zhu, Xiatian and Perez-Rua, Juan-Manuel and Ghanem, Bernard and Song, Yi-zhe and Xiang, Tao},
booktitle=arxiv,
year={2022}
}
|
|
|
Large-Scale Product Retrieval with Weakly Supervised Representation Learning
X Han*,
K.W Ng*
,
Sauradip Nag
,
Z Qu
eBay eProduct Visual Search Challenge
Fine-Grained Visual Categorization Workshop (FGVC9), CVPR 2022
New Orleans, USA
We achieved runners up position in this retrieval challenge. Additionally, we proposed novel solutions for mining pseudo-attributes and treat them as labels, some innovative training recipes and novel post-processing solutions for large-scale product retrieval task
Abstract
/
Code
/
ArXiv /
BibTex
Large-scale weakly supervised product retrieval is a practically useful yet computationally challenging problem.
This paper introduces a novel solution for the eBay Visual Search Challenge (https://eval.ai/challenge/1541/overview) held at the Ninth Workshop on Fine-Grained Visual Categorisation workshop FGVC9 of CVPR 2022.
There are two main challenges to be addressed in this competition: (a) e-commerce is a super fine-grained domain, where there are many products with subtle visual differences; (b) unavailability of instance-level labels for training, but only coarse-grained category-labels and product titles available.
To this end, we adopt a series of empirically effective techniques:
(a) Instead of using text training data directly, thousands of pseudo-attributes are mined from product titles, used as ground truths for multi-label classification.
(b) Several strong backbones and advanced training recipes are incorporated to learn more discriminative feature representations.
(c) Several post-processing techniques including whitening, re-ranking and model ensemble are integrated to further refine model predictions.
Consequently, the final score of our team (Involution King) reaches 71.53\% MAR, ranked at the second position in the leaderboard.
title={Few-Shot Temporal Action Localization with Query Adaptive Transformer},
author={Sauradip Nag and Xiatian Zhu and Tao Xiang},
year={2021},
eprint={2110.10552},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
|
How Far Can I Go ? : A Self-Supervised Approach for Deterministic Video Depth Forecasting
Sauradip Nag*
,
Nisarg Shah*
,
Anran Qi*
,
R Ramachandra
Machine Learning for Autonomous Driving Workshop (ML4AD), NeurIPS 2021
Australia, Virtual
This work introduced the first self-supervised Video Depth Forecasting solution for autonomous driving. It proposed a new Feature Forecasting paradigm of generative modeling for generating future depth maps from rgb frames.
Abstract
/
Code
/
BibTex
In this paper we present a novel self-supervised method to anticipate the depth estimate for a future, unobserved real-world urban scene.
This work is the first to explore self-supervised learning
for estimation of monocular depth of future unobserved frames of a video.
Existing works rely on a large number of annotated samples to generate the probabilistic prediction of depth for unseen frames.
However, this makes it unrealistic due to its requirement for large amount of annotated depth samples of video. In addition, the probabilistic nature of the case, where one past can have multiple future outcomes often leads to incorrect depth estimates.
Unlike previous methods, we model the depth estimation of the unobserved frame as a view-synthesis problem, which treats the depth estimate of the unseen video frame as an auxiliary task while synthesizing back the views using learned pose. This approach is not only cost effective - we do not use any ground truth depth for training (hence practical) but also deterministic (a sequence of past frames map to an immediate future).
To address this task we first develop a novel depth forecasting network DeFNet which estimates depth of unobserved future by forecasting latent features. Second, we develop a channel-attention based pose estimation network that estimates the pose of the unobserved frame. Using this learned pose, estimated depth map is reconstructed back into the image domain, thus forming a self-supervised solution. Our proposed approach shows significant improvements of ~ 5%/8% in Abs Rel metric compared to state-of-the-art alternatives on both short and mid-term forecasting setting, benchmarked on KITTI and Cityscapes.
title={Few-Shot Temporal Action Localization with Query Adaptive Transformer},
author={Sauradip Nag and Xiatian Zhu and Tao Xiang},
year={2021},
eprint={2110.10552},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
Academic Services
|
Teaching:
- COM3013: Computational Intelligence (2022), University of Surrey
- EEEM004: Advanced Topics in Computer Vision (2023), University of Surrey
Technical Programme Committee:
- ML for Autonomous Driving Workshop, NeurIPS
- Conflict of Interest Coordinator, SIGGRAPH North America
Conference Review Services:
- CVPR, ICCV, ECCV, ICLR, NeurIPS, AAAI, ACCV, Eurographics
Journal Review Services:
- Springer Nature Computer Science
- International Journal of Human-Computer Interaction
- IEEE Transactions of Circuit Systems and Video Technology
- IEEE Transactions of Pattern Analysis and Machine Intelligence
- IEEE Transactions of Image Processing
- Elsevier Computer Vision and Image Understanding
- IEEE Transactions on Visualization and Computer Graphics
|
Invited Talks
|
- Dec, 2023 at Eizen AI : "Modern Approaches in Video Understanding" [Slides]
- Jan, 2024 at Adobe : "Future of Video Editing"
- April, 2024 at CMU RI : "CreativeX: Future of Creative Generation/Editing"

|
Copyright © Sauradip Nag. Last updated Aug 2022 | Template provided by Dr. Jon Barron
|
|















.png)