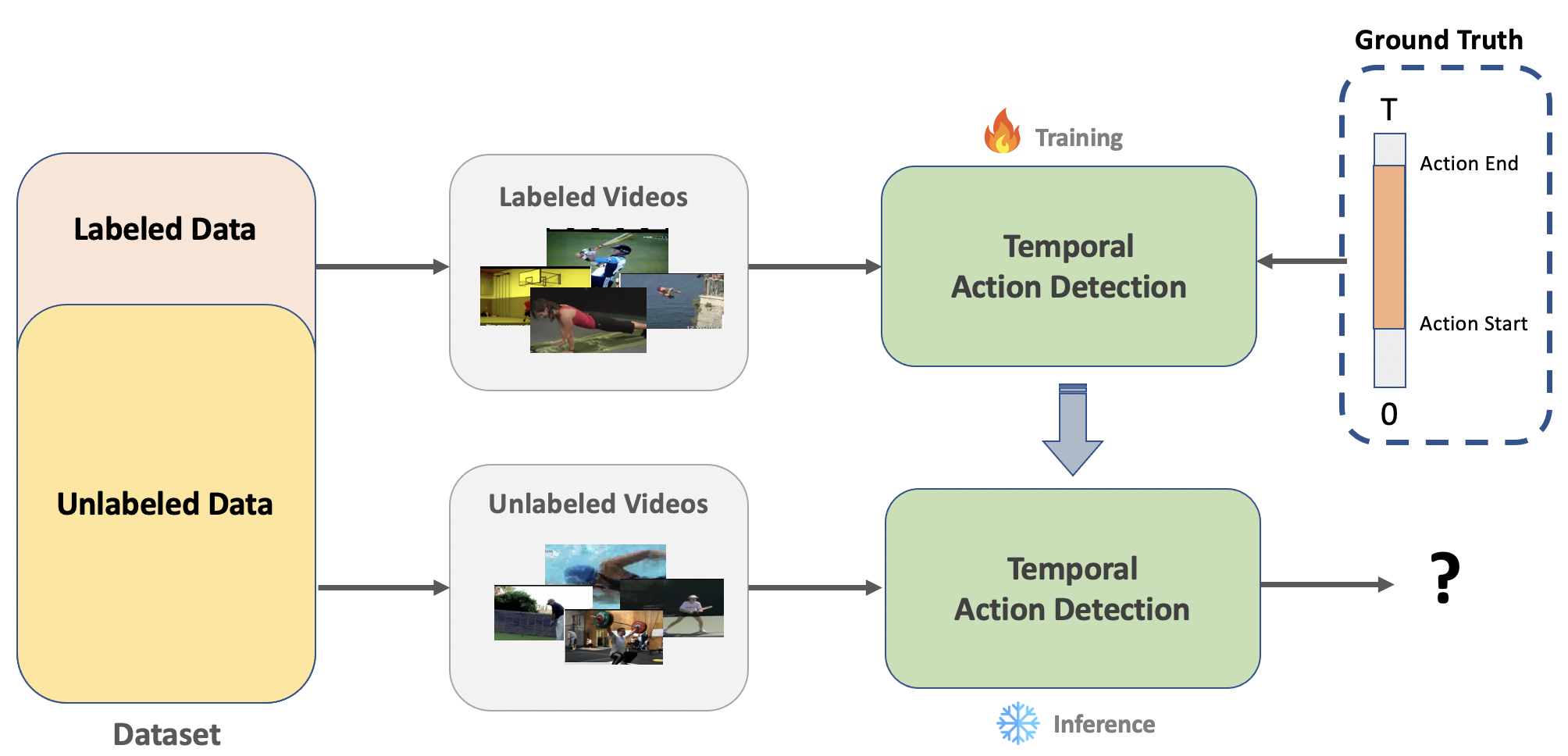
Existing temporal action detection (TAD) methods rely on a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAD (SS-TAD) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SS-TAD is also a much more challenging problem than supervised TAD, and consequently much under-studied. Prior SS-TAD methods directly combine an existing proposal-based TAD method and a SSL method. Due to their sequential localization (e.g., proposal generation) and classification design, they are prone to proposal error propagation. To overcome this limitation, in this work we propose a novel Semi-supervised Temporal action detection model based on PropOsal-free Temporal mask (SPOT) with a parallel localization (mask generation) and classification architecture. Such a novel design effectively eliminates the dependence between localization and classification by cutting off the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for prediction refinement, and a new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our SPOT outperforms state-ofthe-art alternatives, often by a large margin.
Semi-supervised learning (SSL) offers a solution to the annotation cost problem by exploiting a large amount of unlabeled data along with limited labeled data. This has led to an emerging research interest in semisupervised TAD (SS-TAD). Existing methods adopt an intuitive strategy of combining an existing TAD models, dominated by proposal-based methods and a SSL method. However, this strategy is intrinsically sub-optimal and prone to an error propagation problem. As illustrated above, this is because existing TAD models adopt a sequential localization (e.g., proposal generation) and classification design. When extended to SSL setting, the localization errors, inevitable when trained with unlabeled data, can be easily propagated to the classification module leading to accumulated errors in class prediction. To overcome the above limitation, in this work we propose a novel Semisupervised PropOsal-free Temporal Masking (SPOT) model with a parallel localization (mask generation) and classification architecture. Concretely, SPOT consists of a classification stream and a mask based localization stream, established in parallel on a shared feature embedding module. This architecture design has no sequential dependence between localization and classification as in conventional TAD models, therefore eliminating the localization error propagation problem.
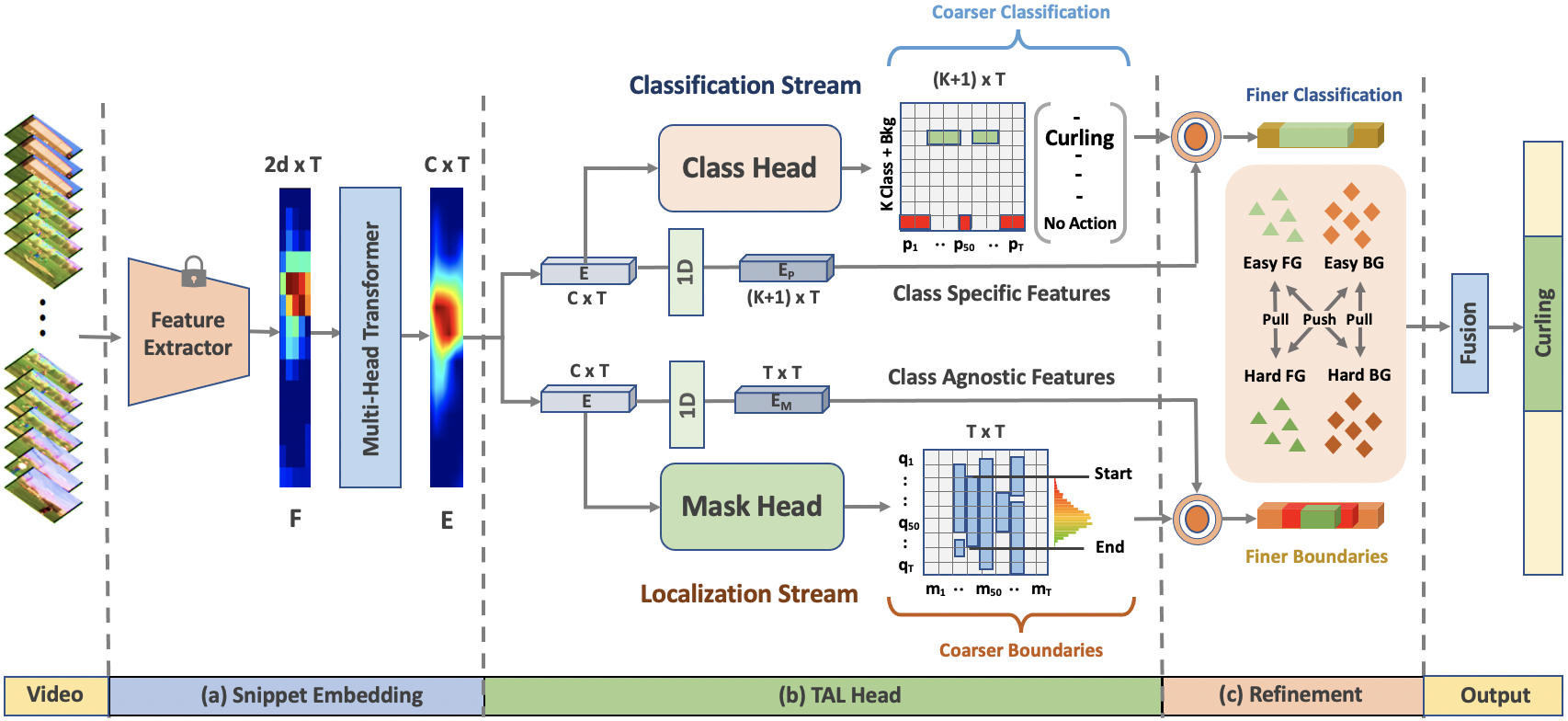
Given an untrimmed video V , (a) we first extract a sequence of T snippet features with a pre-trained video encoder and conduct self-attention learning to obtain the snippet embedding E with a global context. (b) For each snippet embedding, we then predict a classification score P with the classification stream and a foreground mask M with the mask stream in parallel, (c) both of which are further used for boundary refinement. It is based on mining hard&easy foreground (FG) and background (BG) snippets. For SS-TAD, we alternatingly predict and leverage pseudo class and mask labels of unlabeled training videos, along with labeled videos.
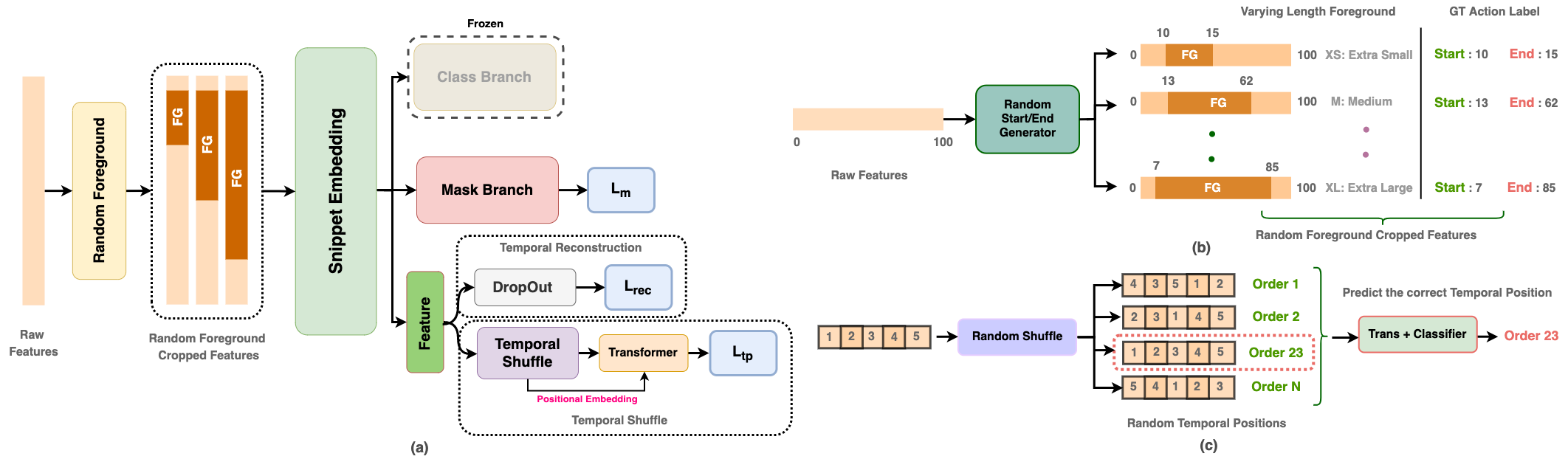
In this work, we also introduce a pretext task based on a novel notion of random foreground specially designed for TAD model pretraining. Given a video feature sequence F , we sample a random token segment (s, e) of varying proportions as foreground and the remaining tokens as background. Cropping out foreground at feature level has shown to be useful in learning discriminative representation. Motivated by this, we zero out the background snippet features whilst keeping for the pseudo foreground. This shares a similar spirit with masked region modeling with a different objective of detecting the location of masked segment. With such a masked feature sequence, our pretext task aims to predict jointly (1) the temporal mask with the start s and end e, (2) the temporal position of each snippet after temporal shuffling, and (3) the reconstruction of snippet feature. We treat each of T temporal positions as a specific positional class, and apply a small Transformer with learnable positional embedding on the shuffled snippet sequences. All zeroed snippet features will become non-zero after the transformer’s processing, preventing the model from learning a trivial solution. The motivation is to preserve the video encoder’s discriminative information in learning global context. By dropping random snippets, the Transformer is forced to aggregate and utilize information from the context to predict the dropped snippets. As a result, the model can learn temporal semantic relations and discriminative features useful for TAD.
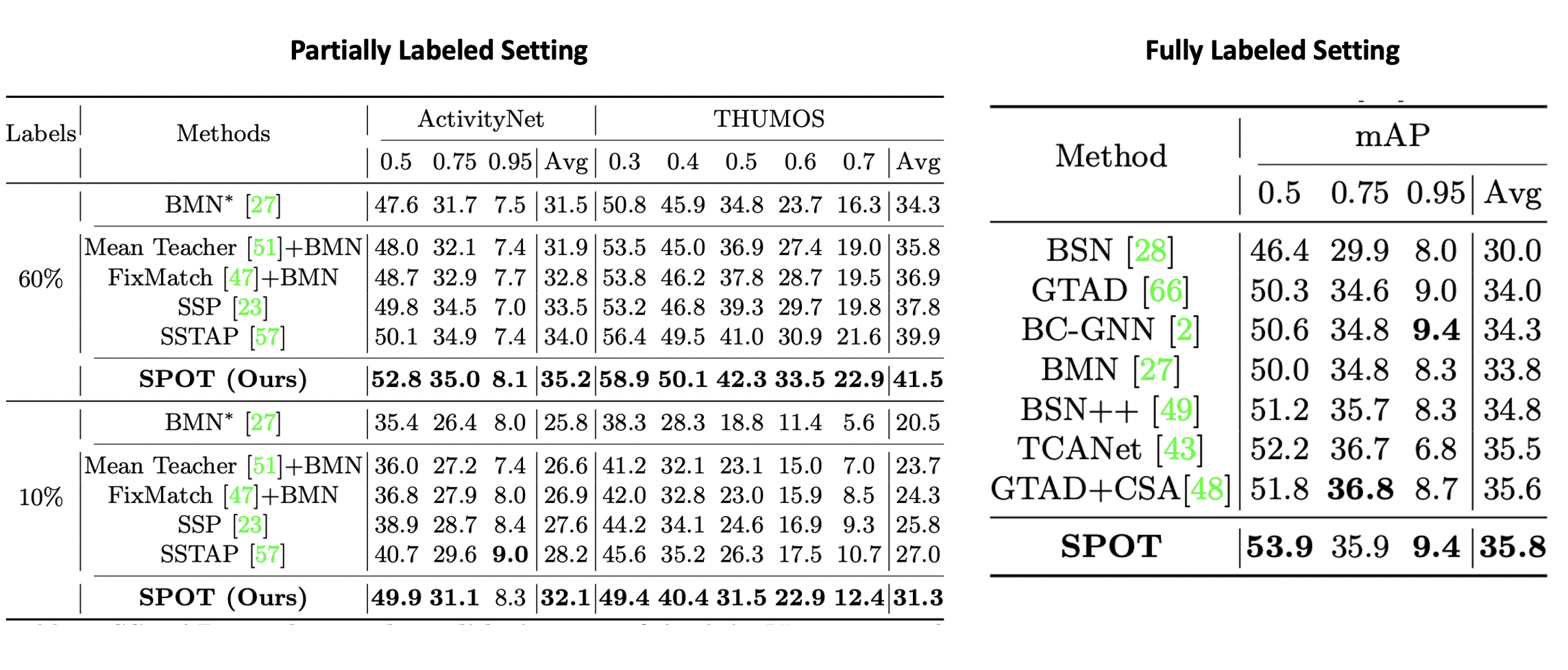
By solving this problem with a new parallel design, our SPOT achieves the new state of the art on both datasets. It is worth pointing out the larger margin achieved by SPOT over all the competitors at the lower supervision case (10% label). For instance, with 10% label, SPOT surpasses the second best SSTAP by 3.9%/4.3% on ActivityNet/THUMOS. A plausible reason is that the proposal error propagation will become more severe when the labeled set is smaller, causing more harm to existing proposal based TAD methods. This validates the overall efficacy and capability of our model formulation in leveraging unlabeled video data for SS-TAD. Besides SS-TAD, our SPOT can be also applied for fully supervised TAD with the pseudo-labels replaced by ground-truth labels while keeping the remaining the same. This test is conducted on ActivityNet. Table below shows that when trained with fully-labeled data, our SPOT can also outperform state-of-the-art TAD methods in the overall result albeit by a smaller margin as compared to the semi-supervised case. This is as expected because in fully supervised setting there would be less proposal error and hence less harm by its propagation.
For reproducing the experimental results, we have provided the pre-extracted video features. Currently we provide TSN based video features and I3D based video features on ActivityNet dataset which are pre-trained on Kinetcis-400. We will make the features available for THUMOS14 soon. The features for TSN can be found in this link and I3D features can be found in this link. We also initiate several dataset splits (10% -90%) for training and testing for the task of temporal action detection. For details on the dataset splits, please check here.
@article{nag2022semi,
title={Semi-Supervised Temporal Action Detection with Proposal-Free Masking},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-Zhe and Xiang, Tao},
journal={arXiv preprint arXiv:2207.07059},
year={2022}
}