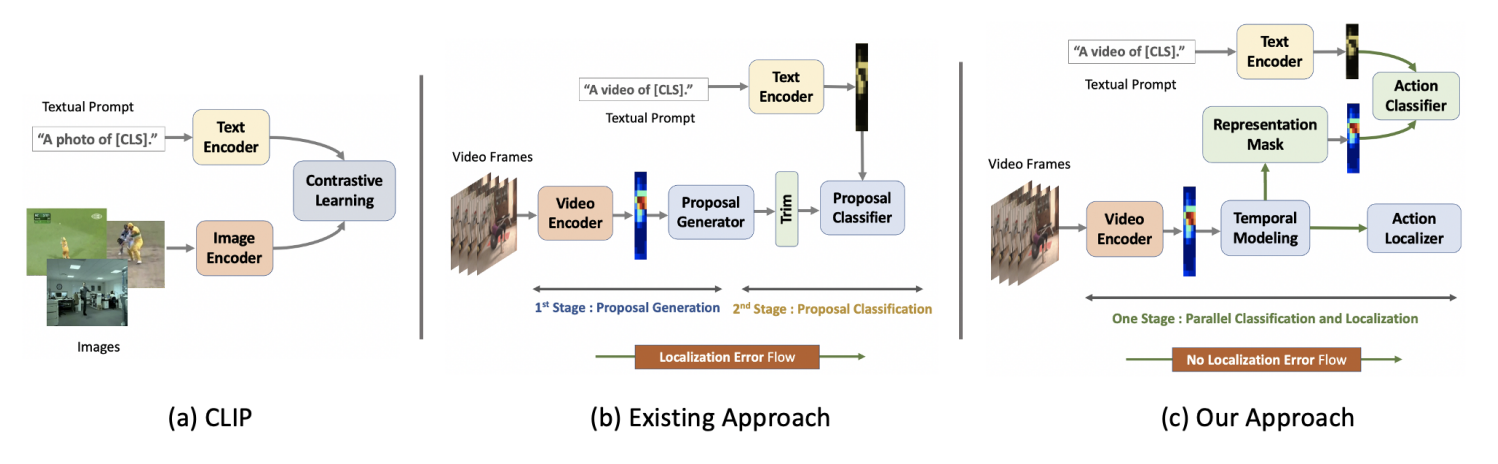
Existing temporal action detection (TAD) methods rely on large training data including segment-level annotations, limited to recognizing previously seen classes alone during inference. Collecting and annotating a large training set for each class of interest is costly and hence unscalable. Zero-shot TAD (ZS-TAD) resolves this obstacle by enabling a pre-trained model to recognize any unseen action classes. Meanwhile, ZS-TAD is also much more challenging with significantly less investigation. Inspired by the success of zero-shot image classification aided by vision-language (ViL) models such as CLIP, we aim to tackle the more complex TAD task. An intuitive method is to integrate an off-the-shelf proposal detector with CLIP style classification. However, due to the sequential localization (e.g., proposal generation) and classification design, it is prone to localization error propagation. To overcome this problem, in this paper we propose a novel zero-Shot Temporal Action detection model via Vision-LanguagE prompting (STALE). Such a novel design effectively eliminates the dependence between localization and classification by breaking the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved optimization. Extensive experiments on standard ZS-TAD video benchmarks show that our STALE significantly outperforms stateof-the-art alternatives. Besides, our model also yields superior results on supervised TAD over recent strong competitors.
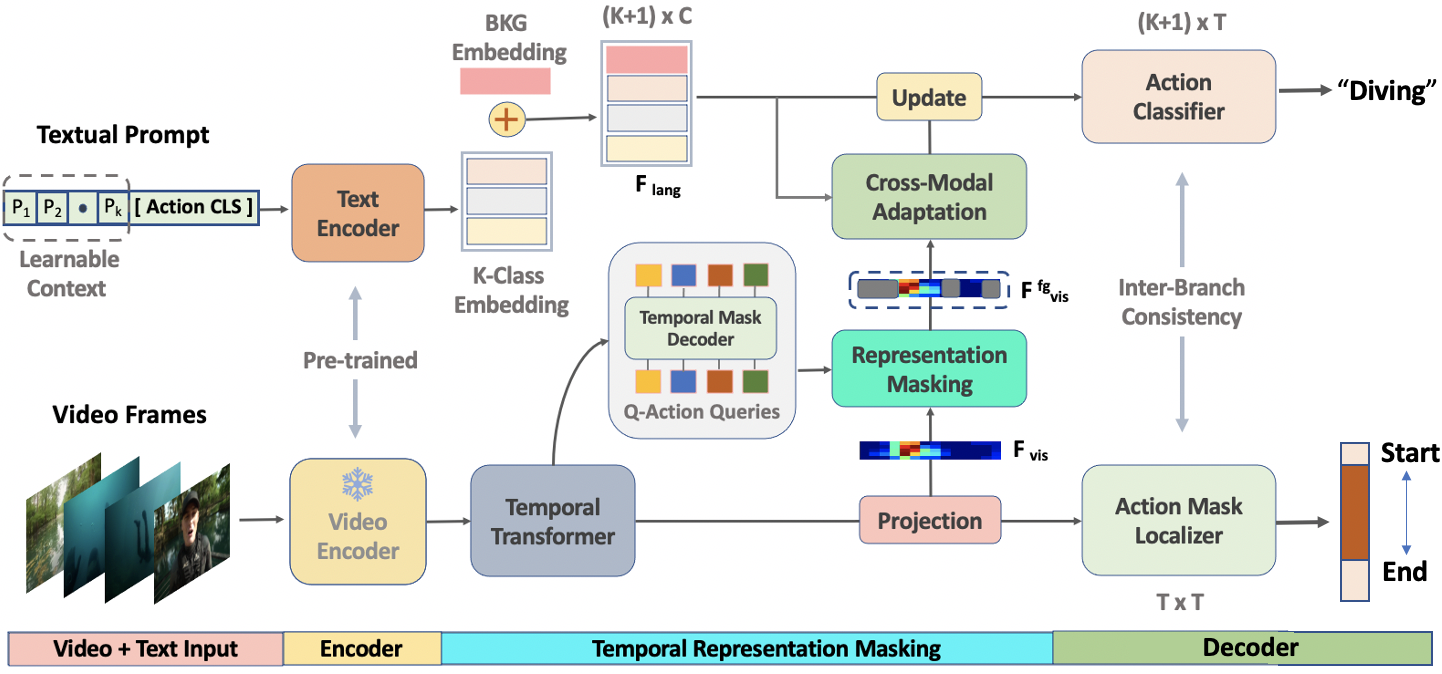
We aim to efficiently steer an image-based ViL model (CLIP) to tackle dense video downstream tasks such as Zero-Shot Temporal Action Detection (ZS-TAD) in untrimmed videos. This is essentially a model adaptation process with the aim to leverage the rich semantic knowledge from large language corpus.
Given an untrimmed video V , (a) we first extract a sequence of snippet features with a pre-trained frozen video encoder and conduct self-attention learning using temporal embedding to obtain the snippet embedding with a global context. (b) For each snippet embedding, we then predict a classification score with the classification stream by masking the foreground feature and aligning with the text encoder embedding to obtain a classifier output. The other branch of snippet embedding is used by action mask classifier to obtain a foreground mask in parallel, (c) both of which are further used for consistency refinement at the feature level.
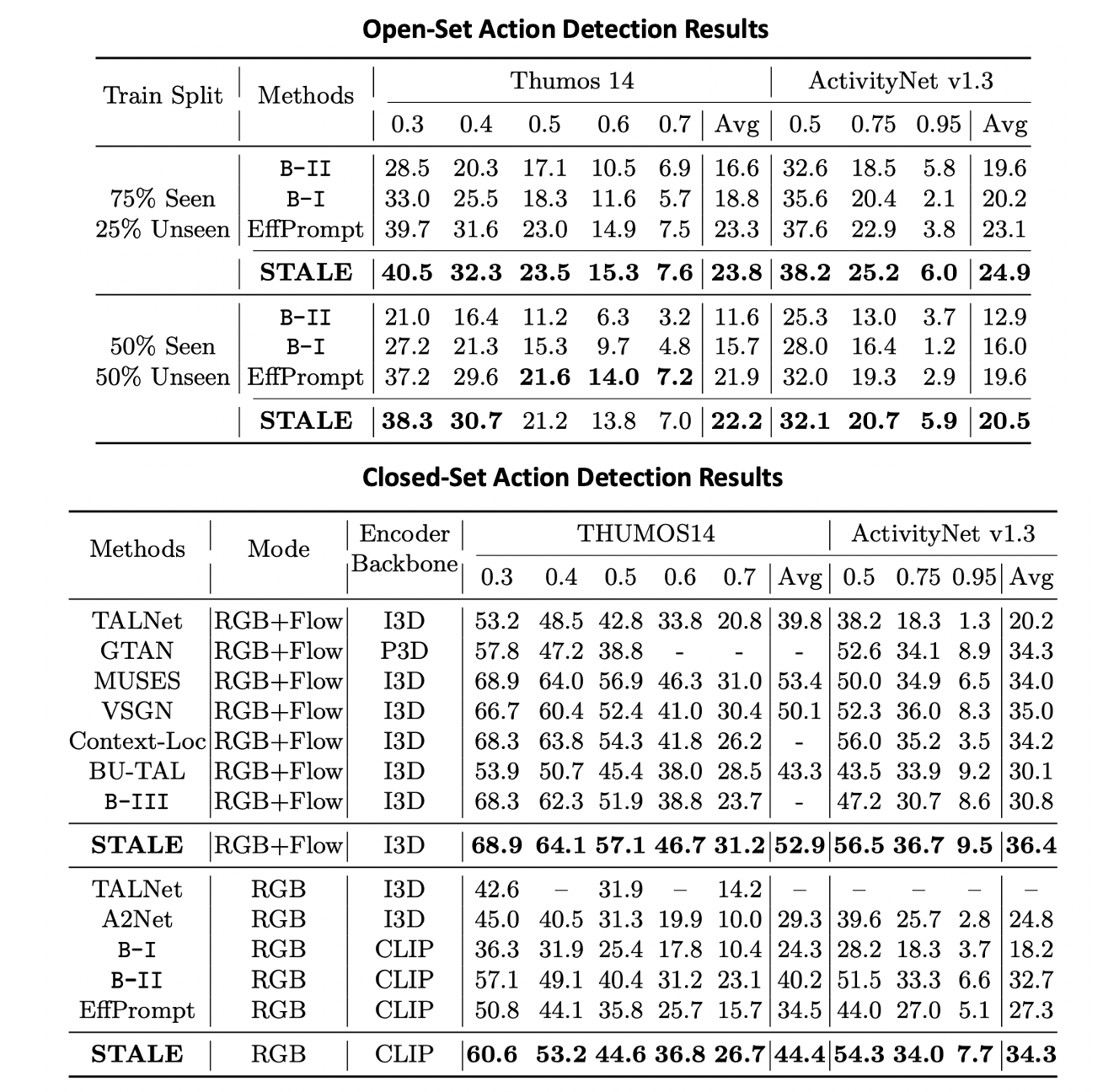
Our proposed STALE is competitive in both closed-set and challenging open-set setting. With both 50% and 75% labeled data it can generalize well to the unseen novel classes. It is even better for closed-set settings where STALE outperforms a lot of current state-of-the-art in fully-supervised TAD indicating the superiority of our model design.
For reproducing the experimental results, we have provided the pre-extracted video features. Currently we provide CLIP based video features and I3D based video features on ActivityNet dataset. We will make the features available for THUMOS14 soon. The features for CLIP can be found in this link and I3D features can be found in this link. We also initiate two dataset splits namely 50% labeled and 75% labeled splits for training and testing for the task of temporal action detection. For details on the dataset splits, please check here.
@article{nag2022zero,
title={Zero-shot temporal action detection via vision-language prompting},
author={Nag, Sauradip and Zhu, Xiatian and Song, Yi-Zhe and Xiang, Tao},
journal={arXiv e-prints},
pages={arXiv--2207},
year={2022}
}